
Jpsonicのスキャンの特徴に関する記事です。
要点としては「Subsonic APIの設計思想は概ね変えないよ」といったところだと思います。Subsonic API互換とうたいつつ別の動きをするフェイクサーバは少なからずあるのですが、Jpsonicではそのような方向性に舵を切ることはありません。ただ「オリジナルのSubsonicと全く同じ動きをするの?」かといえば、必ずしもそうではありません。
- レガシーサーバには厳密にいえば「バグや実装不備の結果その動きをしている」といったものもあります。そういった箇所は修正されます。主にレアケースが多いため普通の使い方で使用感に影響することは少ないかもしれませんが
- ジャンルでアルバムをサマリする辺りの機能は少々珍しい仕様をしています。こういった部分は一般的なジャンル機能を作りましょう、といった修正が今後あるとは思います。そういった場合でもオプションで切り替え式になり旧動作が温存されます
この記事の内容は大きく2つのセクションに分けられます。
- Season 1
- おもにパーサに関する仕様がまとめられています。一般的な仕様のお話です
- Season 2
- 普通に使う分にはあまり必要のない、内部的なお話、現在進行中の取り組みに関する駄文です。これからどうなる的なお話
Subsonic系サーバのスキャン
Subsonic直系のJavaサーバには以下のような分かりやすい特徴があります。これらはなくならないどころか改善対象でしょう。
- フォルダとタグが扱える
- 索引が使用できる
- データベースとは別に強力な検索エンジンを持っている
メディアサーバに限らず、大規模なブラウジングや検索を行うシステムでは、しばしば「結果の欠落を起こさないこと」が要件に入ります。Subsonicはもともと、多少タグが乱れていてもブラウジングや検索で欠落が起にくいデータ仕様を持っています。Jpsonicでは読み(ソートタグ)のクレンジングや補完機能の追加、検索の日本語対応を行い、バニラSubsonicの弱点である日本語使用時の情報欠落を克服しています。メディアサーバにとってストリーミング機能の次に核となる機能であるためです。
Airsonicの検索はJpsonicの検索を当時の仕様に合わせ英語版に移植したものです。スキャンはJpsonicで再設計されているため、メタ処理に関してはかなり内製化が進んでいるといえます。日本のエンジニアは海外の開発に参加すべきだという論調もありますけれども、それはそれ。リスクヘッジも重要です。
Season 1 : パーサの改善
JpsonicのスキャンはSubsonicとほぼ同じ使い方ですが、細部の仕様の明確化、バージョンアップ、バグ改修が行われています。
一方でSubsonicを特徴づけているいくつかの固有の解析仕様(タグ値に不備があるケースの処理等)には手は加えられていません。Subsonicのデータ仕様は目的に沿った一方式として既に確立されたものと想定し、データのリレーションの仕様等はまずは現状維持、という考え方を基本としています。
ゴールデンスタンダードのSubsonicとしての仕様は概ね維持しつつ、緩やかに補強をしていきましょう、というスタンスです。
Jpsonicのタグ解析の方針
Jpsonicが重視するタグ仕様にはお手本にしている仕様があります。これらに合わせて変更が行われる可能性がありますが、私の好みや気まぐれで何かを追加することはありません。
対応フォーマット
設定ページで追加すれば、どのフォーマットでも読み込み可能です。ただし解析が行われるファイル形式は決まっています。
| スキャン対象(デフォルト) | mp3 ogg oga m4a m4b flac wav wma aif aiff aifc dsf dff ape shn mka opus aac |
| 解析可能 | mp3 ogg oga m4a m4b flac wav wma aif aiff aifc dsf dff |
マスターデータの対応フォーマットを増やせば幸せになれるかというとそういうものでもありません。マスターデータとして好ましいフォーマットと、プレイヤーに求められる再生可能フォーマットは別のものです。この分野のソフトウェアや機器がサポートするフォーマットのデファクトスタンダードは「可逆Flac/非可逆Mp3」です。今後の追加パーサ候補はOpusやAACあたりにはなりますが必要性は高くありません。AACはしばしばMP3との比較で語られますが、本来の比較対象は今は亡きATRACです(世情を反映して今世紀初頭に乱立したDRMつき非可逆フォーマットのひとつ。不便な上に無意味なためこのカテゴリーはほぼすべてが滅びた。)マスターデータとしては向かないので、どちらかといえば他の形式にコンバートすることをお勧めします。パフォーマンスを考慮しffprove経由の解析は今後もしません。
楽曲フォーマットとは少し離れますが、プレイリストのフォーマットとして今後もCUEシートはサポートされません。ちなみにMusic Center for PCの仕様にも非対応と明記されています。機器互換が取りづらくグローバルな仕様にはなりにくいと思います。
楽曲ファイルのタグマッピング
OSSソフトウェアでは各種タグ仕様に準じた拡張が行われることがあります。独自の拡張を加えられることがOSSの利点とも言えますが、一般的な音楽プレイヤーや音楽機器、他ソフトとの連携も重要な視点です。実際のところ実用レンジは存在します。
MusicBrainz IdはAirsonicで追加されましたがJpsonicではこれを利用する予定はありません。YAGNI
一方その頃Gracenoteでは・・・
Gracenoteではしばしばガイドラインが示されます。時期によって内容は異なりますが。現在Gracenoteで必須扱いをされているのは、以下の5項目だけです。
- アーティスト名
- アルバム名
- 楽曲名
- ジャンル
- 発売年
Gracenoteの表記法には、タイトルの後に[Disc #]を加えるルール等やキャメルケース必須の項目等、いくつかの追加ルールが示されています。あらゆるデバイスの互換性を考慮しつつ、情報をユーザに認識しやすくさせるための最小ルールになるでしょう。
アーティスト画像は?
アーティスト画像に関する全処理層に設計不備が存在していたためWebページからは外しています。優先度は高くありませんが徐々に修正されています。いつかはWebページにも復活するでしょう。ただし設計上は音楽を管理するための機能と全くの無関係であり、いわゆる「魅力的品質」にあたるものです。コア機能の修正よりも優先されることはありません。UPnPのアーティスト画像は改善が終了しています。
安易な拡張は行われない
iTunesやMusicBrainzのスキーマはとにかく正規化をして情報の解像度を上げる思想です。現状Jpsonicで使用されるタグは概ねSONYよりで、それを超えた余分な部分はカットしています。
色鉛筆で例えると100色セットを使うか12色セットを使うかのような話です。ほとんどの方は12色セットで足りると思います。レアケースのために本当に100色セットの色鉛筆が必要かといいますと。むしろイラストの技術がある方は12色セットで一般人の予想以上のクオリティを出したりもします。おそらく色鉛筆の本数が優劣の決め手になっているわけではないのかと。
Gracenoteのガイドラインは常用する項目を、より少なく想定しているようです。その代わり独特な記法を提示しています。100色セットの色鉛筆を好む方はGracenoteのようなルールに反感を覚えるかもしれません。ですが、Gracenoteが提示しているのは、既存のウェアラブルデバイスやカーオーディオの液晶画面で良好な視認性が確保でき、音声読み上げとの親和性も高められるような最先端の実用仕様だったりします。DBの設計知識のある方は、過度な正規化がデメリットを伴うこともご存じかと思います。Gracenoteのガイドラインは、そういったアンチパターンを避けようとした例としてとらえることもできます。
どちらが賢いという問題ではなく共存も可能ではあります。ただプロダクトの管理コストを考えますと、項目を足すよりも足してしまった後に方針を戻して項目を削る方が遥かに労力がかかります。今後タグ項目は増やさないというわけではありませんが慎重に検討されます。Windowsや、SONYが出しているWindows向け音楽管理アプリが試金石になります。
動画のタグマッピング
今のところffproveの実装次第というところですが、一番多く使われていそうなMP4 version1(QuickTime形式)は問題ありません。今後他のパーサが追加されたとしてもversion1はサポートされるでしょう。
読みの補完処理
索引・検索・ソート等の日本語を扱う全機能の精度を同時に底上げするため、内部的に読みのデータが補完される場合があります。この処理により元の音楽ファイルが編集されることはありません。またダーティデータ対策であるため、もし元々のタグデータが完璧である場合、補完処理は一切行われません。
名称に対して読みはひとつという状態をキープする為、場合によってはスキャン中に以下の追加処理が実行されます。
| 読みの重複の解消 | ライブラリ内すべての人名(アルバム、アーティスト、作曲家)に対応する「読み」をマージする。このときの優先度はファイルの更新日、アルバムアーティスト、アーティスト、作曲者。ユーザの累積修正で意図が反映されやすい順位であり、新たなデータがライブラリに追加された場合、読みは後勝ちで共通化。元データが元々全て統一されていれば何も問題ありません。 |
| 読みの欠落の解消 | 重複の解消後に読みが欠落しているデータが存在する場合(null/そもそもソートタグがない)、他のデータからコピー可能であればコピーする |
| 読みの解析 | 重複と欠落を解消後にまだ欠落が存在する場合はタグだけで解決不可能なケースであるため、名称が日本語の場合日本語エンジンで読みの解析を行う |
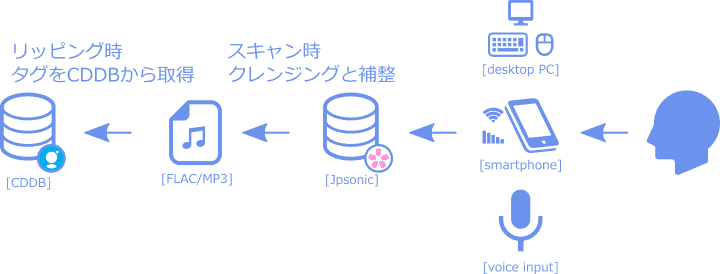
楽曲管理の世界では、そのような役割は既にCDDBが担っています。Music Center for PCのようにGracenoteから任意でデータを引き直せるアプリを利用するか、(滅多にありませんが)データが引けない場合手動でタグを編集してください。
開発時には「Flacが登場した頃からCDDBを利用してリッピングされたデータ」を5000曲前後ピックアップし想定データとして使用しています。現在はデータの誤入力が比較的減りつつありますが、昔にリッピングしたままの曲をお持ちの方も多いでしょう。こういったデータがそれなりに並んで検索できるという仕様になっています。もちろんどうしても無理な部分は確認してタグ修正が必要になりますが、初動の負担をかなり減らすことができるというメリットがあります。
Season 2 : スキャンフローの改善
v111.6.0からv112.0.0にかけて、スキャンフローの大幅な変更が行われています。ここまで着手が遅れたのは、スキャンの内部で行われる全ての処理をノーバグにし例外設計を書き換える必要があったためです。サービスインしているレガシーサーバの改修はしばしば新規開発と手順が逆になります。
なおこれ以降の文章は、メディアサーバが使えればいい、という方には長文の割に有益な情報ではないかもしれません。プログラミング初級者か、あるいは経験がなくても読んでみようというアグレッシブな方向けの内容になります。
スキャン関連の機能は、バグ修正をしたり新規機能の追加はこれ以上難しくなっているので、ワークフロー設計を見直します、というお話です。ユーザ的にはすぐに恩恵が連想できないので何のことやらかもしれません。ワークフロー設計慣れしていれば、あーこうなってるんなら、これからはあれもできちゃうしこれもできちゃうね、というお話になります。
SubsonicとJpsonicのスキャンフローの違い
少しだけデータベースの話が出てきますが、あまり複雑にならない程度にざっくりとした説明をします。旧来のスキャンは大筋以下のような仕組みになっています。
APIでいうところのFile Structure、つまりフォルダブラウジングに使用されるレコードはmedia_fileというテーブルに1パス1レコードで格納されます。typeというフィールドがありここにはALBUMやMUDIC、VIDEOといったメディアの種別が登録されます。アーティスト/アルバム/曲はディレクトリの階層数で判定されているわけではありません。ディレクトリの場合、子にスキャン対象のメディアファイルが存在するかどうかで決定されます。メディアファイルを持っていればアルバム。

新規スキャンの場合ディレクトリやファイルに遭遇する度に、File StructureとID3の解析/登録が行われることになります。アルバムの場合、ディレクトリの最初の子ファイルのタグからアルバムアーティストやアルバム名を転用します。
- 「media_file」にはファイルパス/親パス、種別、タグなど、ライブラリに関するほぼ全ての情報が格納されています
- 「artist」「album」はID3のタグデータです
- File StructureとID3は異なるツリー構造を持ちます。File Structureはパス構造、ID3はタグ値のリレーションです
一見つじつまが合いそうですが、旧来の設計には無理がある箇所がいくつかあります。実際SubsonicやAirsonicでは過去にデータグリッチの報告がいくつかありましたが、好ましくない挙動が複合発生している状況の再現は困難だったりもします。「ここ修正したらここが良くなる!」というバグ修正は簡単ですが、設計品質を向上してからでないと潰しにくい問題も多々あります。
これらを解決するためJpsonicのスキャンフローは大幅に変更されています。要するに処理を細分化し処理ブロックの順序を変え、随時更新と差分更新を分け、重複判定はSQLのフェッチで行い、統計情報はインクリメンタルでなく処理の最後に集約すればよいです。これらを旧来の処理ベースに修正するのはさすがに無理があるので、フロー全体を見直すべきでしょう。
設定画面 : 高度な設定に解説のあるログオプションを有効にすることで、工程ごとのログを閲覧可能です。
ロック実装の違い
Jpsonicのロック機構はより堅牢な実装に変更されています。
- スキャンの2重実行はできません。レガシーサーバに存在していた高速アクセスモードは除去されており、専用のスキャンスレッド以外ではスキャンが実行されないようになっています
- スキャンのロックは内部で他処理と共有されています。同時に取得できるロックはひとつのみです。スキャンの実行中に同時実行すべきでない処理は相互に同時実行できない仕組みになっています。たとえばスキャンの実行中にPodcastのダウンロードが始まることはありません。実装上並列プログラミングが実現可能であっても、ディスクアクセスはシーケンシャルです。IO負荷や整合性を考慮し重要機能は全て直列で実行されます。並列処理設計はそれらの各機能毎に行われます
- スキャンの実行中に致命的なエラー(ネットワーク断線している場合など)が発生した場合、即座に停止するようになっています。原因はログファイルの最後に記録されているでしょう。この場合ロックは自動解除されません。これは現状保存のための意図的なデッドロックであり、スキャンがエラー停止した後に、後追いで別のスキャンが実行されることを防いでいます。スキャンと同時実行すべきでない機能もすべて使用不可能になります。サーバ再起動をすることで解除が可能です
パフォーマンスに関する考え方
今後順次改善が行われるでしょう。
工程ごとのログを閲覧すると分かりますが、区間測定が非常に容易になっています。Jpsonicは他のSubsonic系サーバと異なり、日本語処理や読みの補正、完全なプラットフォーム互換を実現しています。複雑化する一方、SQL発行数はレガシーサーバよりも少ない傾向にあります。ソースコードを短かくすれば速く動くわけではありません。適切な改善で高速化が可能でしょう。
メタ処理に関しては日本語処理は超絶グローバル対応の一歩手前に近く、英語特化のプロダクトよりも多言語対応型に近くなるという優位点があります。また最近のスマホはハード・ソフト両面でスクリーンリーダが性能向上しているため、メディアサーバ側の機能改善でユーザビリティを向上できます。Jpsonicは他サーバよりも目指しているゴールが高いです。
処理を削って速くするのはイージーですが、安易に難しいことを避け続けると発展が阻害されます。結果的に要件として到達点が低くなり20年前30年前に回帰するのは不毛です。Jpsonicは現在のフル要件のまま速く動かす改善を行う方針です。
パフォーマンス改善は、やみくもに行っても仕方がありません。そのため想定環境としてDS220+が使用される予定です。これに関する記事はまた別の機会に。
- 全ての改善を同時に行うわけではなく、優先度の高い順に改修が行われて行きます
- 並列化も部分的に行われて行きます。ブン回すだけが必ずしも最適解ではないので検証が優先されます
- 工程ごとに個別のリファクタリングを行うような部分最適とは別に、スキャンの一部の処理を全く別のロジックへ交換することが容易になっています。場合によっては並列化より速いです
- いうまでもなくファイルの走査が最も時間がかかるのですが、その部分を特定ディレクトリのみのスキャンに変更し、後続処理は丸々同じものを再利用するということが既に可能になっています(というよりタグ編集のような機能は本来そのような設計になっている必要があります)。レガシーサーバではそのようなことはできません。内部的に部分スキャンが実装されることは確実ですが、UIを追加すればアップロード機能を改善したりもできるでしょう
- スキャンのモードを切り替えることによって、更新を行わず、新規追加と削除のみを行うようなロジックを作成することも可能です。効果測定して有効であればそのような機能が追加されるかも知れません。タグ編集を滅多に行わない場合、そちらの方が速い可能性があります
ただしソフトウェア開発では常に正しく動かすことが最優先され、次に検証、次に速度改善という優先度で行われます。まともに動かないものを速くすることに全く意味はありません。
Jpsonic全体で見ると、現状Podcastの機能が非常に弱いです。もともと問題の多い部分でありましたが、近年ではURL直で扱う機会は減りクラウドでの検索が主流になっているため機能全体が陳腐化しています。スキャンの速度改善に関しては、次のバージョンでいくつか並列化オプションが提供されますが、次の次のバージョンからPodcastの全改修が優先される予定です。なぜここまでPodcastの改修が放置され、またサポートするサーバが少ないのか。割と明白で、スキャンを設計できる人でなければPodcastをガチ管理する設計ができないからです。形式上レビューを行っているプロジェクトではそういった人材が複数人必要になります。
逆にPodcastまで改修が終われば、スキャンに関する問題点は大部分がフラットに戻せます。パフォーマンス改善に関して部分最適が以前より容易になったことは確実ですが、それら全てが直近最優先で行われるというわけではない、ということです。ただし並行作業可能なので、三度の飯よりチューニング好きという方はプルリクしてください。
更新履歴
この記事を書き換えたときに以下に追記します。
- v112.0.0
- 設定画面 : 音楽フォルダから「スキャンの仕様」を移動
- 設定画面 : 音楽フォルダ#拡張子とショートカットから「レガシーサーバとの違い」を移動
- 設定画面 : 音楽フォルダ#拡張子とショートカットから「タグマッピング」を移動
コメントはまだありません